
Turing Test
What is the Turing Test?
The Turing Test is a method of inquiry in artificial intelligence (AI) for determining whether or not a computer is capable of thinking like a human being. The test is named after Alan Turing, the founder of the Turing Test and an English computer scientist, cryptanalyst, mathematician and theoretical biologist.
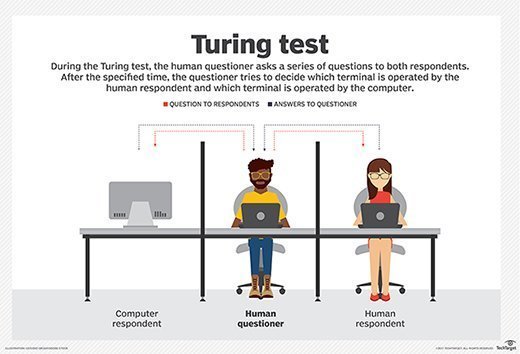
Turing proposed that a computer can be said to possess artificial intelligence if it can mimic human responses under specific conditions. The original Turing Test requires three terminals, each of which is physically separated from the other two. One terminal is operated by a computer, while the other two are operated by humans.
During the test, one of the humans functions as the questioner, while the second human and the computer function as respondents. The questioner interrogates the respondents within a specific subject area, using a specified format and context. After a preset length of time or number of questions, the questioner is then asked to decide which respondent was human and which was a computer.
The test is repeated many times. If the questioner makes the correct determination in half of the test runs or less, the computer is considered to have artificial intelligence because the questioner regards it as "just as human" as the human respondent.
This article is part of
A guide to artificial intelligence in the enterprise
History of the Turing Test
The test is named after Alan Turing, who pioneered machine learning during the 1940s and 1950s. Turing introduced the test in his 1950 paper called "Computing Machinery and Intelligence" while at the University of Manchester.
In his paper, Turing proposed a twist on what is called "The Imitation Game." The Imitation Game involves no use of AI, but rather three human participants in three separate rooms. Each room is connected via a screen and keyboard, one containing a male, the other a female, and the other containing a male or female judge. The female tries to convince the judge that she is the male, and the judge tries to disseminate which is which.
Turing changes the concept of this game to include an AI, a human and a human questioner. The questioner's job is then to decide which is the AI and which is the human. Since the formation of the test, many AI have been able to pass; one of the first is a program created by Joseph Weizenbaum called ELIZA.
Limitations of the Turing Test
The Turing Test has been criticized over the years, in particular because historically, the nature of the questioning had to be limited in order for a computer to exhibit human-like intelligence. For many years, a computer might only score high if the questioner formulated the queries, so they had "Yes" or "No" answers or pertained to a narrow field of knowledge. When questions were open-ended and required conversational answers, it was less likely that the computer program could successfully fool the questioner.
In addition, a program such as ELIZA could pass the Turing Test by manipulating symbols it does not understand fully. John Searle argued that this does not determine intelligence comparable to humans.
To many researchers, the question of whether or not a computer can pass a Turing Test has become irrelevant. Instead of focusing on how to convince someone they are conversing with a human and not a computer program, the real focus should be on how to make a human-machine interaction more intuitive and efficient. For example, by using a conversational interface.
For more on artificial intelligence-related terms, read the following articles:
Variations and alternatives to the Turing Test
There have been a number of variations to the Turing Test to make it more relevant. Such examples include:
- Reverse Turing Test -- where a human tries to convince a computer that it is not a computer. An example of this is a CAPTCHA.
- Total Turing Test -- where the questioner can also test perceptual abilities as well as the ability to manipulate objects.
- Minimum Intelligent Signal Test -- where only true/false and yes/no questions are given.
Alternatives to Turing Tests were later developed because many see the Turing test to be flawed. These alternatives include tests such as:
- The Marcus Test -- in which a program that can 'watch' a television show is tested by being asked meaningful questions about the show's content.
- The Lovelace Test 2.0 -- which is a test made to detect AI through examining its ability to create art.
- Winograd Schema Challenge -- which is a test that asks multiple-choice questions in a specific format.
How is the Turing Test used today?
Although the variations of the Turing Test are often more applicable to our current understanding of AI, the original format of the test is still used to this day. For example, the Loebner Prize has been awarded annually since 1990 to the most human-like computer program as voted by a panel of judges. The competition follows the standard rules of the Turing Test. Critics of the award's relevance often downplay it as more about publicity than truly testing if machines can think.
At a competition organized by the University of Reading to mark the 60th anniversary of Turing's death in 2014, a chatbot called Eugene Goostman that simulates a 13-year-old boy passed the Turing Test, in the eyes of some, when it fooled 33% of the judges. This so-called first pass has been met with much criticism from those who argue that there weren't enough judges, that other machines have performed better at the test in the past and that the test is invalid for only lasting five minutes.
In 2018, Google Duplex successfully made an appointment with a hairdresser over the phone in front of a crowd of 7,000. The receptionist was completely unaware that they weren't conversing with a real human. This is considered by some to be a modern-day Turing Test pass, despite not relying on the true format of the test as Alan Turing designed it.
GPT-3, a natural language processing model created by OpenAI, is thought by some to have the best chance of beating the test in its true form of any technology that we have today. But, even with its advanced text-generation abilities, many have criticized the machine because it can be tricked into answering nonsensical questions and therefore would struggle under the conditions of the Turing Test.
Despite much debate about the relevance of the Turing Test today and the validity of the competitions that are based around it, the test still stands as a philosophical starting point for discussing and researching AI. As we continue to make advances in AI and better understand and map how the human brain functions, the Turing Test remains foundational for defining intelligence and is a baseline for the debate about what we should expect from technologies for them to be considered thinking machines.





