
Sergey Nivens - Fotolia
5 modern ETL tools for microservices data integration
Batch-style ETL tools don't provide the data integration capabilities microservices require. Learn about a handful of modern tools that can handle a plethora of data sources in real time.

Data integration and processing is a complex challenge enterprise IT organizations face when they manage microservices applications at scale. Modern microservices applications process data from a wide variety of sources, such as mainframes, proprietary databases, email messages, other applications and webpages. Failure to properly integrate any one of these sources can cause some serious problems.
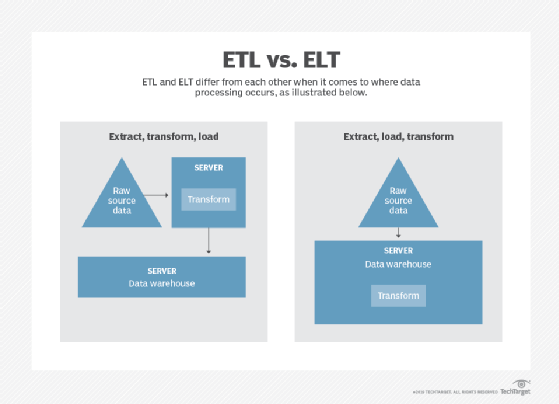
Proper data integration should not only combine data from different sources, but should also create a single interface through which you can view and query it. The most commonly used technique is extract, transform and load (ETL). This decades-old method of data integration has life in modern architectures.
Traditional vs. modern ETL tools
Most traditional ETL tools work best for monolithic applications that run on premises. These tools are designed to integrate data in batches. Examples of incumbent batch ETL tools include IBM InfoSphere DataStage, Microsoft SQL Server Integration Services, Oracle Data Integrator and Informatica PowerCenter.
This range of tools arose to solve problems specific to monolithic applications. Using them for microservices data integration can be a time-intensive and error-prone activity. What's more, batch data doesn't meet modern demands for the real-time data access microservices applications need. Enterprise organizations and customers now expect to the so-called freshest data possibly available.
Modern ETL tools enable you to store, stream and deliver data in real time, because these tools are built with microservices in mind. The data integration approach includes real-time access, streaming data and cloud integration capabilities. The tools also integrate well with cloud data warehouses like Amazon RedShift, Snowflake Inc., Google BigQuery and Azure SQL.
These tools account for the ever-growing number of data sources and streams, which is something that traditional ETL tools lack given their batch approach for monoliths. Modern ETL tools consequently offer better security as they check for errors and enrich data in real time. These streaming, data pipeline ETL tools include Apache Kafka and the Kafka platform Confluent, Matillion, Fivetran and Google Cloud's Alooma.
Distributed streaming with Kafka
The open source Kafka distributed streaming platform is used to build real-time data pipelines and stream processing applications. Initially conceived as a messaging queue, it quickly evolved into a full-fledged streaming platform that handles trillions of events a day in highly distributed microservices applications.
Kafka integrates disparate systems through message-based communication, in real time and at scale. Though the concept isn't exactly new, Kafka's method is the basis for many modern tools like Confluent and Alooma.
Easy-to-use Confluent
Because Kafka is still at the early adoption stage, there's a small pool of developers with the skills to properly use it. Organizations can get around the learning curve with Confluent Inc.'s data-streaming platform that aims to make life using Kafka a lot easier.
Confluent expands upon Kafka's integration capabilities and comes with additional tools and security measures to monitor and manage Kafka streams for microservices data integration. Confluent comes in a free open source version, an enterprise version and a paid cloud version.
Matillion for cloud warehouse
Matillion Ltd. offers an ETL tool built specifically for cloud data warehouses like Amazon Redshift, Google BigQuery and Snowflake. Matillion is built on an Amazon Machine Image, which is designed for quick setup.
Mattilion enables you to load data into a preferred data warehouse from dozens of sources, such as AWS Simple Storage Service and Amazon Relational Database Service, Google Analytics, Salesforce, SAP and even social media platforms. It is easy to orchestrate and automate data load and transform while also integrating with and relying on other systems and AWS services.
Point and click with Fivetran
Fivetran Inc.'s SaaS data integration tool promises point-and-click ETL processes through a simple and straightforward GUI. It quickly connects the application to a data source, sets up integrations, transforms the data into the preferred format and sends it to its destination.
Fivetran features a fully automated data pipeline built for analysts. When working with multiple microservices that each require multiple data integrations, Fivetran's efficiency can be a life saver.
Ultra-fast query Alooma
Alooma is another modern ETL platform built on Kafka, and it features streaming capabilities like enriching data and performing ultra-fast queries in real time. Alooma integrates with popular databases such as MongoDB, Salesforce, REST, iOS and Android. Google Cloud acquired Alooma Inc. in 2019.
The Alooma platform provides horizontal scalability by handling as many events as needed at small cost increments. This is a key requirement for microservices apps that may scale out sporadically. Designed for security, Alooma does not store any data permanently. It also encrypts any data in motion and carries System and Organization Controls 2 Type 2 and EU-U.S. Privacy Shield certifications.






