Splunk execs outline the vendor's direction and new capabilities at its annual user conference, including the general availability of Data Fabric Search and Data Stream Processor.
Splunk pushed forward on its Data-to-Everything platform with product releases and a new acquisition.
The developments came as the cybersecurity and IT operations vendor hosted its annual .conf19 user conference in Las Vegas.
Among the capabilities Splunk introduced and demonstrated on the .conf19 stage Oct. 22 were the Data Fabric Search (DFS) and Data Stream Processor technologies that are core elements of the vendor's new Data-to-Everything approach.
Splunk is also growing its platform by acquisition. On Oct. 21, Splunk said it is acquiring privately held streaming data vendor Streamlio, one of the leaders of the Apache Pulsar project. Pulsar was originally developed by Yahoo and is competitive with the Kafka streaming project and its primary commercial vendor, Confluent. Terms of the Streamlio acquisition were not publicly disclosed. The Streamlio deal comes after other recent acquisitions by Splunk, including a $1.05 billion acquisition of SignalFx in August.
The Streamlio acquisition gives Splunk more capabilities in processing high volumes of data in real time, complementing existing and new capabilities such as those from SignalFx, Gartner analyst Federico De Silva said.
"This is in order to process data that comes from cloud-native architectures with highly distributed and massive data producing volumes," De Silva said. "It also allows Splunk to handle many more types of data types, again complementing SignalFx and other capabilities."
Overall De Silva said he has a positive view of Splunk's broad Data-to-Everything strategy and what it means for the San Francisco-based vendor and its users.
"This is a pretty big evolution in their strategy, as they want to become a data platform for many more use cases beyond security and IT ops," De Silva said.
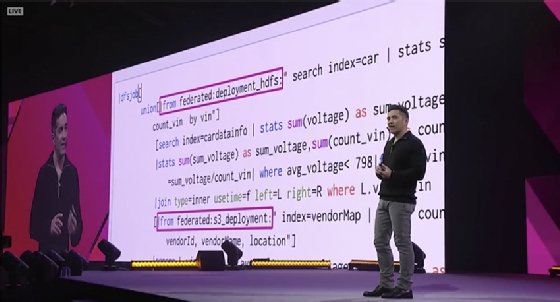
Tim Tully, senior vice president and CTO at Splunk, demonstrates federated search at .conf19
Data-to-Everything
Splunk CEO Doug Merritt outlined in a live-streamed keynote what the Data-to-Everything approach means.
"There is no way that any parts of our lives can be separated from data going forward," Merritt said. "Are you prepared for this new data age because in this coming age there will only be two types of companies -- those that seize the opportunity to make things happen with data and those that no longer exist."
This is a pretty big evolution in their strategy, as they want to become a data platform for many more use cases beyond security and IT ops
Federico De SilvaAnalyst, Gartner
The core premise of Data-to-Everything is about capturing data from different sources and then providing tools that can enable users to derive actionable insights. The Data-to-Everything strategy takes full form in the Splunk Enterprise 8.0 platform which became generally available on Oct. 22.
Tim Tully, senior vice president and CTO at Splunk, provided some insight into several key new features, including the Data Stream Processor, that are part of the platform during his .conf19 keynote. Tully said the Data Stream Processor enables users to easily create data pipelines in a full graphical user interface environment.
"It allows you to move aggregation, ETL [extract, transform, load, preprocessing and alerting use cases into the stream," Tully said. "It is built for heterogenous ingress and egress of data and we've seen a lot of our key early beta customers use it as a data routing message bus."
Data Fabric Search
Another feature reaching general availability is the DFS capability that Splunk first announced as a beta at .conf18. One of the key attributes of DFS is federated search capabilities.
Tully explained that it's now possible to use the Splunk Search Processing Language to write queries that federate the search over a Splunk index, Hadoop Distributed File System (HDFS) and Amazon S3 today, with more connectors to come in the future.
"What we've seen from our largest customers who ingest petabytes of data per day is that the time to execute their queries has come down by up to 95%, just by adding DFS to Splunk Enterprise," he said.
The conference is being held Oct. 21 to 24 at the Venetian Resort Las Vegas and Sands Expo Convention Center.