spiral model
The spiral model is a systems development lifecycle (SDLC) method used for risk management that combines the iterative development process model with elements of the Waterfall model. The spiral model is used by software engineers and is favored for large, expensive and complicated projects.
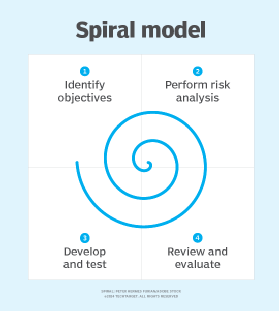
When viewed as a diagram, the spiral model looks like a coil with many loops. The number of loops varies based on each project and is often designated by the project manager. Each loop of the spiral is a phase in the software development process.
The spiral model enables gradual releases and refinement of a product through each phase of the spiral as well as the ability to build prototypes at each phase. The most important feature of the model is its ability to manage unknown risks after the project has commenced; creating a prototype makes this feasible.
Uses of the spiral model
As mentioned before, the spiral model is best used in large, expensive and complicated projects. Other uses include:
- projects in which frequent releases are necessary;
- projects in which changes may be required at any time;
- long term projects that are not feasible due to altered economic priorities;
- medium to high risk projects;
- projects in which cost and risk analysis is important;
- projects that would benefit from the creation of a prototype; and
- projects with unclear or complex requirements.
Spiral model phases
When looking at a diagram of a spiral model, the radius of the spiral represents the cost of the project and the angular degree represents the progress made in the current phase. Each phase begins with a goal for the design and ends when the developer or client reviews the progress.
Every phase can be broken into four quadrants: identifying and understanding requirements, performing risk analysis, building the prototype and evaluation of the software's performance.
Phases begin in the quadrant dedicated to the identification and understanding of requirements. The overall goal of the phase should be determined and all objectives should be elaborated and analyzed. It is important to also identify alternative solutions in case the attempted version fails to perform.
Next, risk analysis should be performed on all possible solutions in order to find any faults or vulnerabilities -- such as running over the budget or areas within the software that could be open to cyber attacks. Each risk should then be resolved using the most efficient strategy.
In the next quadrant, the prototype is built and tested. This step includes: architectural design, design of modules, physical product design and the final design. It takes the proposal that has been created in the first two quadrants and turns it into software that can be utilized.
Finally, in the fourth quadrant, the test results of the newest version are evaluated. This analysis allows programmers to stop and understand what worked and didn’t work before progressing with a new build. At the end of this quadrant, planning for the next phase begins and the cycle repeats. At the end of the whole spiral, the software is finally deployed in its respective market.
Steps of the spiral model
While the phases are broken down into quadrants, each quadrant can be further broken down into the steps that occur within each one. The steps in the spiral model can be generalized as follows:
- The new system requirements are defined in as much detail as possible. This usually involves interviewing a number of users representing all the external or internal users and other aspects of the existing system.
- A preliminary design is created for the new system.
- A first prototype of the new system is constructed from the preliminary design. This is usually a scaled-down system, and represents an approximation of the characteristics of the final product.
- A second prototype is evolved by a fourfold procedure: (1) evaluating the first prototype in terms of its strengths, weaknesses, and risks; (2) defining the requirements of the second prototype; (3) planning and designing the second prototype; (4) constructing and testing the second prototype.
- The entire project can be aborted if the risk is deemed too great. Risk factors might involve development cost overruns, operating-cost miscalculation and other factors that could result in a less-than-satisfactory final product.
- The existing prototype is evaluated in the same manner as was the previous prototype, and, if necessary, another prototype is developed from it according to the fourfold procedure outlined above.
- The preceding steps are iterated until the customer is satisfied that the refined prototype represents the final product desired.
- The final system is constructed, based on the refined prototype.
- The final system is thoroughly evaluated and tested. Routine maintenance is carried out on a continuing basis to prevent large-scale failures and to minimize downtime.
Benefits of the spiral model
As mentioned before, the spiral model is a great option for large, complex projects. The progressive nature of the model allows developers to break a big project into smaller pieces and tackle one feature at a time, ensuring nothing is missed. Furthermore, since the prototype building is done progressively, the cost estimation of the whole project can sometimes be easier.
Other benefits of the spiral model include:
- Flexibility - Changes made to the requirements after development has started can be easily adopted and incorporated.
- Risk handling - The spiral model involves risk analysis and handling in every phase, improving security and the chances of avoiding attacks and breakages. The iterative development process also facilitates risk management.
- Customer satisfaction - The spiral model facilitates customer feedback. If the software is being designed for a customer, then the customer will be able to see and evaluate their product in every phase. This allows them to voice dissatisfactions or make changes before the product is fully built, saving the development team time and money.
Limitations of the spiral model
Limitations of the spiral model include:
- High cost - The spiral model is expensive and, therefore, is not suitable for small projects.
- Dependence on risk analysis - Since successful completion of the project depends on effective risk handling, then it is necessary for involved personnel to have expertise in risk assessment.
- Complexity - The spiral model is more complex than other SDLC options. For it to operate efficiently, protocols must be followed closely. Furthermore, there is increased documentation since the model involves intermediate phases.
- Hard to manage time - Going into the project, the number of required phases is often unknown, making time management almost impossible. Therefore, there is always a risk for falling behind schedule or going over budget.







